


Every business today deals with data, whether it comes from websites, mobile apps, sales systems, or customer interactions. This data is often scattered across different platforms and stored in different formats. On its own, raw data does not provide much value. It needs to be organized and refined before it can be used for decision making.
This is where ETL becomes important. ETL is a process that helps companies collect data from multiple sources, clean it, and store it in a way that makes analysis easier. If you are new to data concepts, understanding ETL is a good starting point because it forms the foundation of many data systems used today.
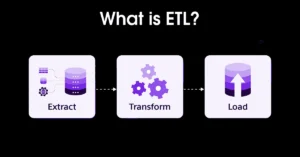
What is ETL?
ETL stands for Extract, Transform, Load. It is a structured process used to move data from one place to another while improving its quality along the way.
In simple terms, ETL takes raw data from different systems, processes it into a consistent format, and stores it in a central location such as a data warehouse. This makes it easier for analysts, developers, and decision makers to work with reliable information.
Think of ETL as a pipeline. Data flows in from different sources, gets refined in the middle, and comes out ready for use at the end.
Why is ETL Important?
ETL plays a key role in helping organizations make sense of their data. Without it, data would remain scattered and difficult to use.
One of the main benefits of ETL is that it brings data together into a single system. This makes it easier to track performance, generate reports, and identify trends. When all data is in one place, teams can work more efficiently and avoid confusion.
Another important reason ETL is used is to improve data quality. Raw data often contains errors, duplicates, or missing values. The transformation stage helps fix these issues, which leads to more accurate insights.
ETL also supports scalability. As businesses grow, the amount of data they generate increases. A well designed ETL process can handle this growth without slowing down operations.
How ETL Works: Step-by-Step
The ETL process is divided into three main stages. Each stage has a specific purpose and plays a role in preparing data for analysis.
1. Extract
The first step is extraction. This is where data is collected from different sources. These sources can include databases, cloud applications, APIs, spreadsheets, and more.
During this stage, the goal is to gather all relevant data without making changes to it. The data is taken as it is, even if it is messy or incomplete.
For example, a company might extract customer data from its website, purchase data from its billing system, and interaction data from its mobile app. All of this information is collected so it can be processed later.
2. Transform
The transformation stage is where the real work happens. In this step, the extracted data is cleaned and converted into a usable format.
Data transformation can involve many tasks. These include removing duplicates, correcting errors, standardizing formats, and applying business rules. The goal is to make the data consistent and reliable.
For instance, one system might store dates in one format while another uses a different format. Transformation ensures all dates follow the same structure. This consistency is important for accurate analysis.
This stage may also involve combining data from multiple sources or filtering out unnecessary information.
3. Load
The final step is loading. Once the data has been cleaned and prepared, it is moved into a target system such as a data warehouse or data lake.
There are different ways to load data. A full load replaces all existing data with new data. An incremental load only updates the data that has changed since the last update.
For example, a company might load updated sales data into its reporting system every day. This allows managers to track performance using the latest information.
Also Read: Top Robotics Companies Shaping the Future of Automation
ETL vs ELT: What’s the Difference?
ETL is often compared with ELT, which stands for Extract, Load, Transform. While both processes deal with moving and preparing data, the order of steps is different.
In ETL, data is transformed before it is loaded into the destination system. This approach is commonly used in traditional data environments where storage and processing power are limited.
In ELT, data is loaded first and then transformed within the target system. This approach is more common in modern cloud platforms, which have the capacity to handle large volumes of raw data.
The choice between ETL and ELT depends on the tools being used and the specific needs of the organization.
Common ETL Tools
There are many tools available that help automate ETL processes. These tools reduce manual work and make it easier to manage data pipelines.
Some widely used ETL tools include Apache NiFi, Talend, Informatica, Microsoft SQL Server Integration Services, and AWS Glue. Each tool offers different features, but they all aim to simplify data extraction, transformation, and loading.
Choosing the right tool depends on factors such as budget, data volume, and technical requirements.
Real-World Use Cases of ETL
ETL is used across many industries and applications. It plays an important role in business intelligence by preparing data for dashboards and reports. Companies rely on these insights to make informed decisions.
In data warehousing, ETL helps store structured data in a centralized system. This allows teams to access consistent and reliable information.
Healthcare organizations use ETL to combine patient records from different systems. This improves accuracy and helps provide better care.
E-commerce platforms use ETL to analyze customer behavior. By understanding how customers interact with their websites, businesses can improve user experience and increase sales.
Benefits of ETL
One of the main benefits of ETL is improved data accuracy. Clean and consistent data leads to better analysis and more reliable results.
ETL also saves time. Automated processes reduce the need for manual data handling, which allows teams to focus on more important tasks.
Another advantage is better insight generation. When data is organized and accessible, it becomes easier to identify trends and patterns.
ETL also supports compliance. Many industries have strict regulations regarding data handling. ETL helps ensure that data is processed and stored correctly.
Challenges of ETL
Despite its advantages, ETL can be challenging to implement and maintain. One common issue is complexity. Managing data from multiple sources requires careful planning and coordination.
Performance can also be a concern, especially when dealing with large datasets. If not optimized, ETL processes can become slow and inefficient.
Data quality is another challenge. If transformation rules are not well defined, errors can be introduced into the data.
Maintenance is also important. ETL pipelines need regular updates to keep up with changes in data sources and business requirements.
Best Practices for ETL
To build an effective ETL process, it is important to follow certain best practices. Start by defining clear goals. Understand what data you need and how it will be used.
Focus on data quality at every stage. Validate and clean data to ensure accuracy.
Automation can help improve efficiency. Using ETL tools reduces manual effort and minimizes errors.
Monitoring is also important. Keep track of performance and fix issues as they arise.
Using incremental loading can save time and resources. Instead of processing all data repeatedly, focus only on new or updated data.
ETL in Modern Data Architecture
ETL has evolved with advancements in technology. In modern systems, it is often integrated with cloud platforms that offer scalability and flexibility.
Cloud based ETL allows organizations to process data in real time. This is useful for applications that require immediate insights.
Data lakes are another important component. ETL helps organize raw data stored in these systems, making it easier to analyze.
ETL also plays a role in artificial intelligence and machine learning. Clean and structured data is essential for building accurate models.
Future of ETL
The future of ETL is closely tied to the growth of data and cloud computing. Real time data processing is becoming more common as businesses seek faster insights.
Automation is also increasing. Many modern tools use artificial intelligence to optimize ETL pipelines.
Serverless technologies are reducing the need for manual infrastructure management. This makes ETL more accessible to organizations of all sizes.
While ELT is gaining popularity, ETL continues to be relevant, especially in environments where data needs to be cleaned before storage.
Conclusion
ETL is a fundamental process in data management. It helps transform raw data into meaningful information that organizations can use to make better decisions.
By extracting data from multiple sources, transforming it into a consistent format, and loading it into a central system, ETL ensures that data is reliable and ready for analysis.
Understanding ETL is essential for anyone working with data. It provides the foundation for analytics, reporting, and many modern technologies.
Also Read: Cross-Platform Mobile Development: A Practical Guide for Real-World Projects



